Kafka
kafka的优势
- 避免单点问题支持集群部署
- 高性能
- 按批发送消息,消费消息
Kafka的架构图
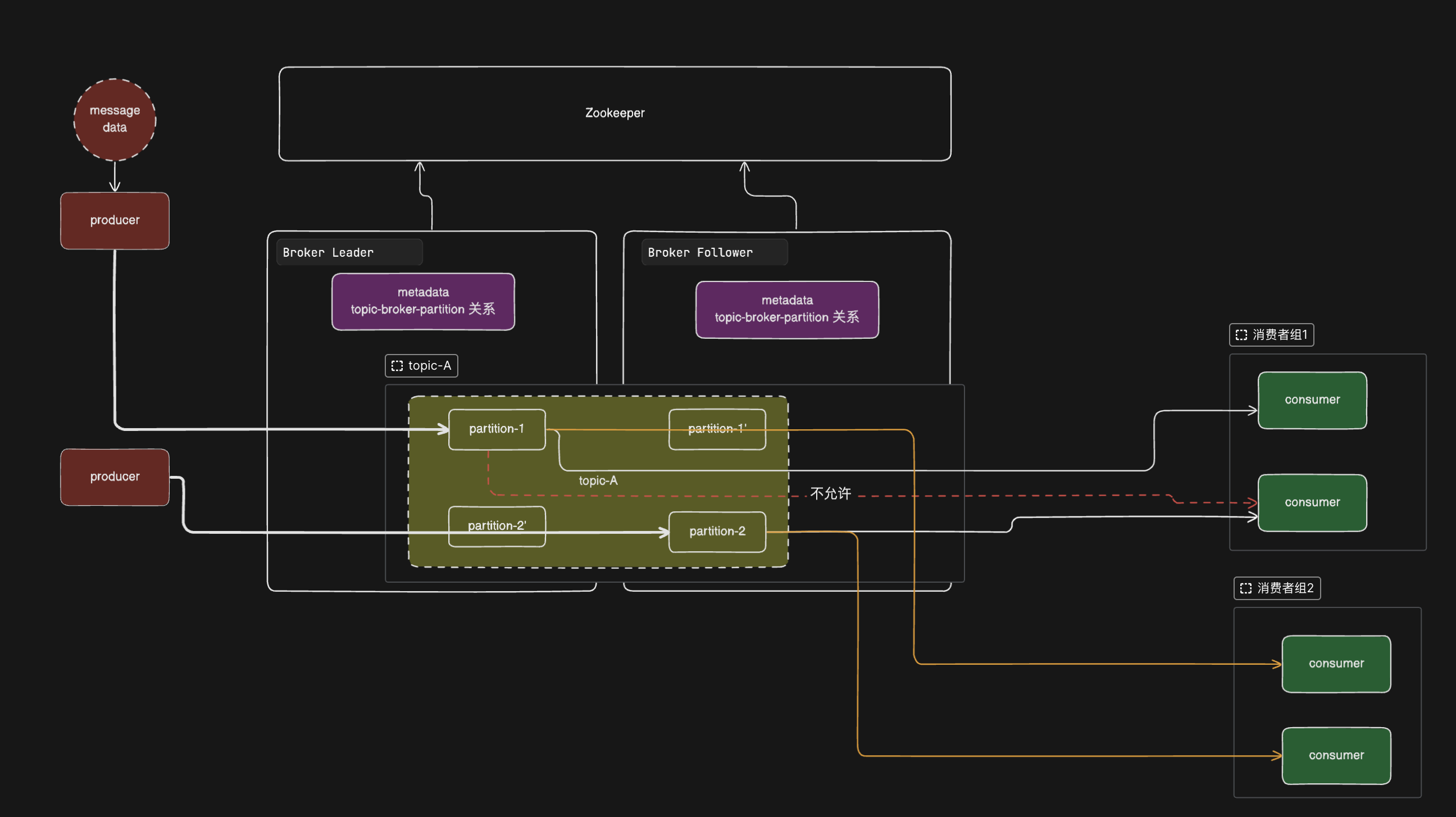
kafka的AKF划分
y轴:基于业务划分的topic
x轴:基于出主机的节点复制,鸡蛋不放在一个篮子里
x轴:解决y轴的某个topic消息量大的时候分之处理:partition
但是在x轴上,虽然可以使用读写分离的方案来提高读写性能,但是会有数据一致性的问题。对于Kafka而言,规定了读写只能发生在主节点的partition
消费者端的消息消费需要维护offset需要考虑的问题
- 丢失问题: 消费者下游 业务没有执行完成,但是修改了offset
- 重复消费问题:异步维护,拉取到消息之后,5秒内先执行业务,5s之后持久化offset
offset 放在哪里维护?
- 使用Kafka自己的broker存贮每个topic每个patition每个组的offset
- 可以选择第三放存放:Redis、MySQL
offset什么时候维护?
异步维护,拉取到消息之后,5秒内先执行业务,5s之后持久化offset,可能导致重复消费
同步维护,完成业务操作和同时写入offset
offset维护的粒度
- 按照消息的维度
- 按照poll批次批量维护
- 按照partition offset的粒度维护
Kafka的ISR
ISR: In-Sync Replicas 基于连通性和活跃性 决定应该具体等到多少个ACK
Kafka的OSR
OSR: out-Sync Replicas 超过多久没有心跳/交互、同步,
Kafka的AR
Assigned Replicas 面向分区的副本集合,即:同一个partition下的所有副本(就是replica,不区分leader或follower)
AR = ISR + OSR
kafka的LW
Kafka生产者的Ack设置
0代表不等待Broker确认,在这种情况下,不能保证服务器已经收到了记录。
-1和1都需要等待Broker返回确认。
1代表这个确认是Broker将消息写到主(Leader)磁盘后返回,不用等待从(Follower)同步。
-1则代表应答需要等待所有正常同步的副本ISR(In sync replica)写到消息日志(Log)后才会返回。
Kafka持久层的日志和索引
index
timestampindex
log
Kafka的生产者参数
疑问:
为什么需要使用Kafka?
为什么Kafka吞吐量更高?相比其他的消息中间件?
topic分区之后消息的顺序性如何保证?
基于整体无序,局部有序的特征的原则。kafka同topic同分区内部是有序的,分区外部是无序的。
把无关的数据分散到不同的分区,以追求最大的并行效率
有关的数据,一定要按照原有的顺序放到同一个分区。
如何保证消息的顺序(生产者生产消息入队的有序 消费者消费的有序)
- 生产的 亲密性
- 一个分区不能由多个消费者消费
消费者和分区是怎么绑定消费关系的
kafka是按批次推送数据
消息是怎么分配到不同的partition?
如何给给定的消息是没有设置key,按照顺序
nextValue,轮询打入到不同的partition如果消息设置了key,消息key hash取模分配的partition数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 内部维护一个消息序列自增nextValue
int nextValue = this.nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return ((PartitionInfo)availablePartitions.get(part)).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 如果消息设置了key,消息key hash取模分配的partition数量
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
消费者是怎么绑定partition的?