ZooKeeper
1.什么是ZooKeeper
ZooKeeper 是一个针对分布式应用程序的开源的分布式协调服务,
分布式应用可以基于ZooKeeper的api构建高级别的同步、配置管理、分组和命名服务。
它是基于类似文件系统的目录树结构
2.ZooKeeper的出现是为了解决什么问题?
服务协调容易出现竞争条件和死锁。 ZooKeeper 背后的初衷就是减轻分布式应用程序从头开始实现协调服务的目的。
3.Zookeeper的tags
分布式协调服务 基于内存 文件树结构存储 高性能、高可用性、严格有序
4.Zookeeper架构
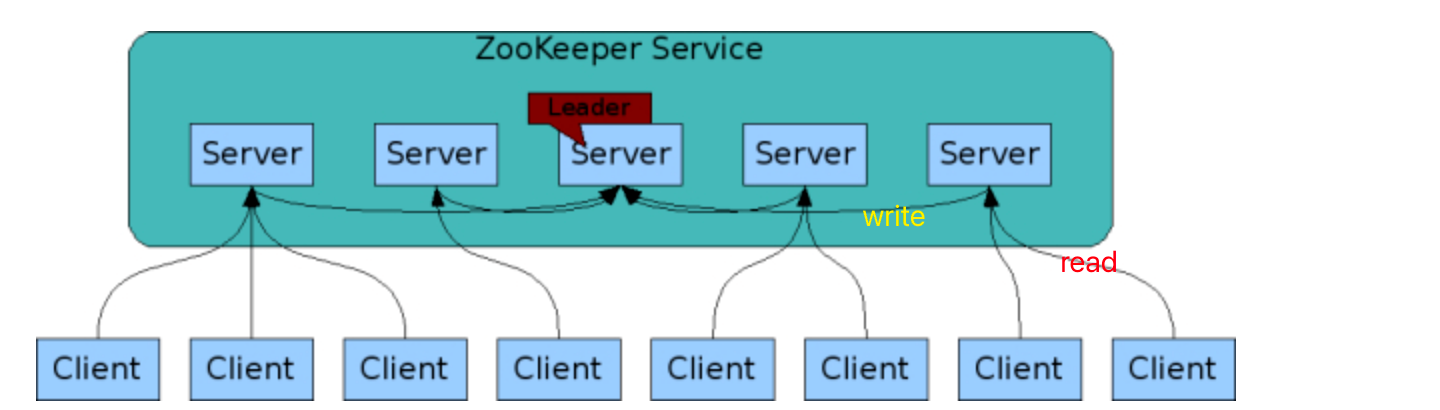
3.ZooKeeper的设计目标
- 简单,易于理解、使用。 ZooKeeper 允许分布式进程通过共享的分层命名空间相互协调,该命名空间的组织方式与标准文件系统类似。命名空间由数据寄存器( znode)组成,它们类似于文件和目录。ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低延迟数。
- 支持集群部署,以保证高可用:ZooKeeper 的实现非常注重高性能、高可用性、严格有序的访问。 ZooKeeper 的性能方面意味着它可以在大型分布式系统中使用。可靠性方面使其不会成为单点故障。严格的排序意味着可以在客户端实现复杂的同步原语。
4.ZooKeeper 提供哪些特性?
- 顺序一致性保证:由于更新操作必须由主节点执行,来自客户端的更新将按照发送的顺序被执行。
- 原子性保证:对于主从节点更新要么所有节点都成功,要么都失败。不会部分成功。
- 单一系统映像(统一视图): 无论客户端连接到哪个服务器,客户端都将看到相同的服务视图。即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。
- 可靠性(持久性)保证: 一旦应用更新,它将从那时起持续存在,直到客户端覆盖更新。
- 及时性(最终一致性):保证系统的客户视图在一定的时间范围内是最新的。
5.配置文件
1 | # The number of milliseconds of each tick |
zk扩展性
角色:
Leader
Follower
Observer: 不参与投票选举,只提供查询能力。
可靠性
攘其外 必先安其中内 且国不可一日无主
快速选举Leader
只有leader的时候才能正常对外提供服务。
数据可靠性
拜占庭将军问题
古代做皇帝,车马慢,书信慢。那么在快马传递情报的时候很可能在中间被篡改信息。
指的是网络通信中出现了不可靠的消息。
Paxos
基于消息传递的一致性算法,Paxos的前提是没有拜占庭将军问题,就是说Paxos只有在一个可信的计算环境中才能成立,这个环境是不会被入侵所破坏的。https://www.douban.com/note/208430424/?_i=1726458-DIncSZ
ZAB协议(原子广播协议)
作用与可用状态(有主状态)
1.客户端发起一个create /node-name ‘xxx’
2.修改请求转发给leader
3.leader 自增sessionId (zxid),假设此时是1001
4.Leader向Followers发起写日志通知(进入到主-FollowerN 的通知队列),Follower收到来自队列的通知开始写磁盘,Follower回送Leader收到消息,再通知Follower写内存,Follower写完再回复「写成功」状态回队列里。
5.通知FollowN成功,FollowN再回复客户端成功
ZK的Leader选举过程总结
- 通过3888端口建立两两通信
- 只要任何节点投票,就会触发准Leader节点发起为自己投票
- 推选谦让制,如果事务ID相同的时候,再比较myid
ZK的Watch机制
目的是为了实现节点的统一视图,每个客户端都会watch每个节点,再节点在被创建、修改删除的时候,zkServer会推送event,通知客户端节点信息的更新。
ZK分布式协调
分布式配置
分布式锁
疑问:
zk是主从架构模型那么如何避免主节点的单点故障问题?如何快速地选出主节点?
当zk进入到无主模型的时候服务是拒绝服务状态,是怎么做到快速恢复的?,他是怎么保证高可用?官方报告出来在200ms内能恢复
为什么规定一个node能存放的数据是1M?
为了快速同步数据,快速恢复
基于临时节点实现的分布式锁原理是怎么样的?
临时节点随着客户端的session存在而存在,当session消失的时候,临时节点消失。
对于写入请求,必须由主节点执行,所以写入操作必须排队由主节点单线程操作,从而避免了多线程资源竞争
原子性保证原理是怎么样的?他是如何一次更新保证所有的数据的强一致性?为什么不会破坏可用性?
过半通过 最终一致性
二进制安全
客户端给什么存什么。
sync 指令follower怎么知道需要sync?
为什么投票需要使用不同的3888端口?不使用2888?