5.Redis中的List、Set、ZSet、Hash实际使用场景
List 结构
常见的操作:
- LRANGE :
LRANGE key start stop
# 从头到尾取出key为:testlist 的元素LRANGE testlist 0 -1- LPUSH :
LPUSH key element [element ...]从上个元素左侧添加元素,或者说从头部添加。
LPUSH testlist 1 2 3 4# 这里容易理解成摆放顺序为 1 2 3 4,实则不然。LRANGE testlist 0 -11) "4"2) "3"3) "2"4) "1"-
LPOP:
LPOP key从集合的最左侧弹出一个元素。 -
LTRIM:
LTRIM key start stop,截取元素,类似 java List 的 subList(),截取的下标包前不包后。 -
LLEN:
LLEN key获取 list 元素个数。 -
LREM:
LREM key count element删除 count 个 element 元素。当 count 为负数,从后往前删指定的 |count| 个元素 -
BLPOP/BRPOP:
BLPOP key [key ...] timeout,阻塞式地从左右侧弹出一个元素,当key里没有元素能弹出时一直阻塞等待,或者重试等待timeout秒,没有元素弹出则返回nil。
List类型使用场景:
- 基于 redis
反向命令实现先进后出的队列结构:like:lpush,lpop,基于Redis的消息队列其实就是这个原理。 - 基于 redis
同向命令实现后进先出的栈结构:like:lpush,lpop - 基于下标操作的数组结构
- 阻塞队列
- 推荐文章列表的分页查询。
Set 结构
Set常用操作:
- SADD 添加元素:
SADD key member [member ...] - SISMEMBER 是否是这个集合的子集:
SISMEMBER key member - SMEMBERS 获取集合的所有元素:
SMEMBERS key - SMOVE 从source移动元素到destination:
SMOVE source destination member - SPOP 从集合中取出count个元素并移除:
SPOP key [count]。 - SRANDMEMBER 从集合中查询(并不移除)一个随机元素出来。
- SUNION 求N个集合的并集:
SUNION key [key ...] - SINTER 求N个集合的交集:
SINTER key [key ...] - SDIFF 求N个集合的差集:
SDIFF key [key ...]
Set结构的使用场景:
-
取集合的交并差运算:共同好友
-
用户随机抽奖
准备key为
prizevalue为:存放每位参与用户ID的Set集合。每次抽count个名额。-
a:奖品多人少:
srandmember prize count,count为负数时单人可以重复中奖。 -
b:奖品少人多:
spop prize count, -
c:抽取之后,奖品仍在奖池,下次还能重复中。
srandmember prize count -
d: 抽取之后,奖品直接从奖池拿走,不能重复中同一个奖,公司年会场景。
spop prize count
-
-
用户系统:用户打标签。某两位用户有相同的关注内容,那么后期用来做内容精准推荐。
ZSet
常用操作命令:
-
ZADD 添加元素,并设置分值
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]元素添加进去之后是升序排放的。score用于标识元素的摆放位置,越小越靠左,score相同则按照字符顺序排序。 -
ZRANGE:升序列举元素;
ZRANGE key start stop [WITHSCORES]
ZADD testsort 4 zhangsan 1 lisi 2 zhaoliu(integer) 3# 列举元素(不显示分数)ZRANGE testsort 0 -11) "lisi"2) "zhaoliu"3) "zhangsan"# 列举元素,并附带分值一起查询出来ZRANGE testsort 0 -1 withscores1) "lisi"2) "1"3) "zhaoliu"4) "2"5) "zhangsan"6) "4"# 测试相同的分值zadd num 1 1 1 2 1 0 1 3 1 9 1 4ZRANGE num 0 -11) "0"2) "1"3) "2"4) "3"5) "4"6) "9"- ZREVRANGE :降序列举元素
ZREVRANGE key start stop [WITHSCORES]
# 降序列举ZREVRANGE testsort 0 -1 withscores-
ZCOUNT:获取满足范围的数据个数
ZCOUNT key min max -
BZPOPMAX:阻塞式去除一个分数最高的。
BZPOPMAX key [key ...] timeout
ZSet使用场景:
- 歌曲排行榜:歌曲的热的选取播放量维度排序,一首歌曲播放之后进行incrc操作。
- 阻塞队列:高校录取填报了志愿的学生,分数从高往低取出,然后做一系列的资质分析【手动狗头】。
ZSet排序是怎么实现的?
- Skip List(跳表)
假如就按照单链表存放属性有序的元素,最坏的结果得遍历一次整个链表,复杂度为O(N)。 那么怎么优化?MySQL是通过索引加速,这么一想是不是会有异曲同工的解决方案?
通俗地研究一把跳表是个什么东西: 为了加快链表索引速度,那么最先能想到的办法就是二分。怎么个二分法?跳跃性地有序维护!
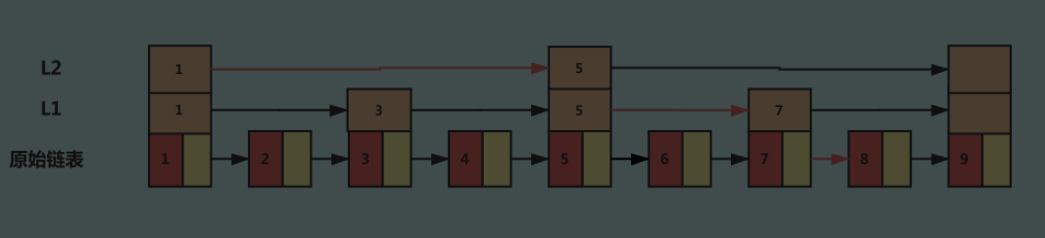
此时,我们假设要查找节点8,我们可以先在索引层遍历,当遍历到索引层中值为 7 的结点时,发现下一个节点是9,那么要查找的节点8肯定就在这两个节点之间。我们下降到链表层继续遍历就找到了8这个节点。原先我们在单链表中找到8这个节点要遍历8个节点,而现在有了一级索引后只需要遍历五个节点。
Hash 结构
常用命令操作:
- HSET设置key的field值:
HSET key field value [field value ...] - HGET获取key的field值:
HGET key field - HINCRBY 自增一个field 的int/folat,增幅为:increment
HINCRBY/HINCRBYFLOAT key field increment
Hash结构的使用场景:
-
存放商品明细信息,商品的浏览量,收藏量,下单量,可以通过field的自增来累计。
-
用户的购物车信息。
- 以客户id作为key,每位用户创建一个hash存储结构存储对应的购物车信息。
- 将商品编号作为field,购买数量作为value进行存储
- 添加商品:追加全新的field与value
- 浏览:遍历hash
- 更改数量:自增/自减,设置value值
- 删除商品:删除field
- 清空:删除key
- 全选:hgetall
- 购物车总数量:hlen
- 增加某件商品的数量:hincrby
userId1:{ “productId1”:2 “productId2”:3}但是购物车商品明细数据并没有得到加速,商品信息还要二次查询数据库,面向对象再优化一把。把商品信息和购买数量再包装一层呗。
userId1:{ { “count_productId1”:2, “info_productId1”:"{}"}, { “count_productId2”:3, “info_productId2”:"{}"},}