9.Redis数据分片
一、再谈单节点的 Redis 存在的问题
- 单点故障
- 数据容量问题
- 连接数、请求压力问题
前文提及的主从+哨兵架构,解决了单点问题和请求压力问题,但是数据容量仍然是 1:1 的克隆数据,数据容量问题依旧存在,数据并没有分摊到各个节点。
二、如何解决单点数据容量问题
A:基于客户端的方案
1.业务拆分数据
从业务的角度不同的模块按约定好的逻辑落入不同的Redis 节点。
比如:评论业务用一个redis阶段,商品信息业务用另外一个节点,购物车用另外一个节点。
2.通过Hash算法路由
- 2.1 Modula:将hash(ID)%redis节点数
弊端:redis节点数改变的话,数据就分配规则就被打破了。
- 2.2 Random:随机分配
使用场景:消息队列。
数据随机的落入到不同的节点,对于客户端而言无所谓数据落在那一台节点,只需要知道key就能拿到数据。
- 2.3 Ketama:一致性Hash算法将数据分摊到不同的节点。
规划一个虚拟的环形节点,将节点和数据参与位置分配算法。
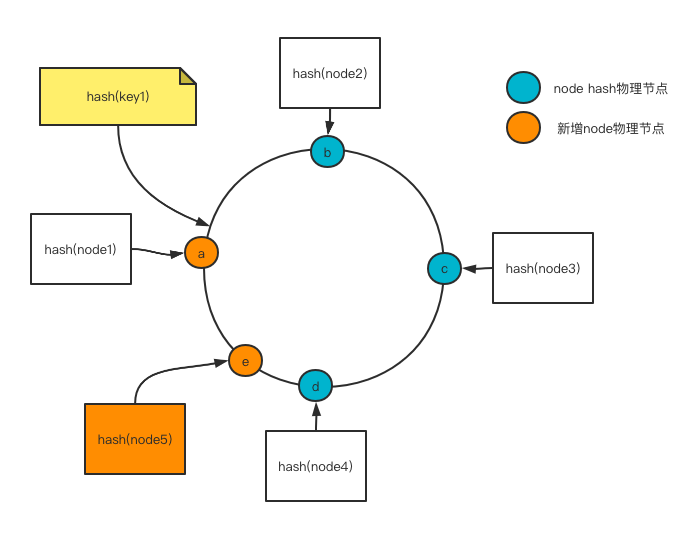 优点:增加节点可以分担其他节点的压力,不会造成全局洗牌,原本的数据还在最初规划出的物理节点中。
优点:增加节点可以分担其他节点的压力,不会造成全局洗牌,原本的数据还在最初规划出的物理节点中。
一致性Hash缺点:
- 击穿的风险,原本数据是在a节点的,但是增加了节点导致后续的数据源从节点e获取,但是e又没有获取到数据,从而将请求打入到了数据库,从而可能导致击穿缓存拖垮数据的风险。
方案:当在计算出的离最近节点没有获取到的数据,尝试从离计算值最近的2个物理节点去去获取数据。
- 数据倾斜 -> 缓存雪崩
假设:我们刚上线的时候Redis节点只有两台,而我的的数据的key是可能是基于某一个基准在往上做增长,那么就会导致数据大概倾斜的落在某一个节点,最极端的可能导致所有的请求都打在了这一个节点,从而拖垮此节点,从而引发缓存雪崩。
方案:上述问题的关键点在于物理节点少,数据落点
非黑即白,那么能否增加逻辑上的节点?只有两台物理节点,但是还有不同的端口啊,ok,那就在每个IP之后再添加随机的数字去生成逻辑节点。
B:安排专人去充当数据路由的的角色
上述的解决方案中,我们把数据路由的逻辑架在了客户端,但是对于客户端而言,连接可以看成是几类数据直接怼在了服务端。这对于服务端而言连接的开销也是不小的。革命尚未成功,还需努力。
租客谁都找房东去房东带看房子怎么能受得了对吧,那就找中介呗

那么此时只要关注的就是这个中介proxy代理的性能。
那么是否有已经造好的Proxy轮子?
C.Redis的Cluster
我们前面说的通过hash取模计算数据所属节点的方案中,缺陷在于增减节点需要对所有的数据rehash,再根据rehash的结果迁移数据。那么是否能够将数据预先规划?
假设最初节点只有两个,要预先规划数据所属节点,先将数据预先规划为10槽位(slots),在Redis Cluster里其实是分配了16384个slots,后续增加节点则直接从2个节点各自分一段范围的数据过来,雨露均沾嘛。然后分到的数据进行rehash,再数据迁移到新的节点。
这样子的话,只要增加了节点。数据还是存在高频的rehash呀?而且假如要对两个相同类型的数据进行求交并补运算的话,redis也没办法做。好比两个物理库的mysql数据没办法inner join。
对数据加标签(hash tag)而不是单纯的直接通过hash(key),Redis不想被吐槽它不行呀。这个锅得用户自己背,你想要对这部分的数据做运算,做事务处理那么你就应该尽可能的将数据划分到一个物理机上。你自己给数据加tag,从而对同一个tag做hash运算的时候能保证在一个物理机上。
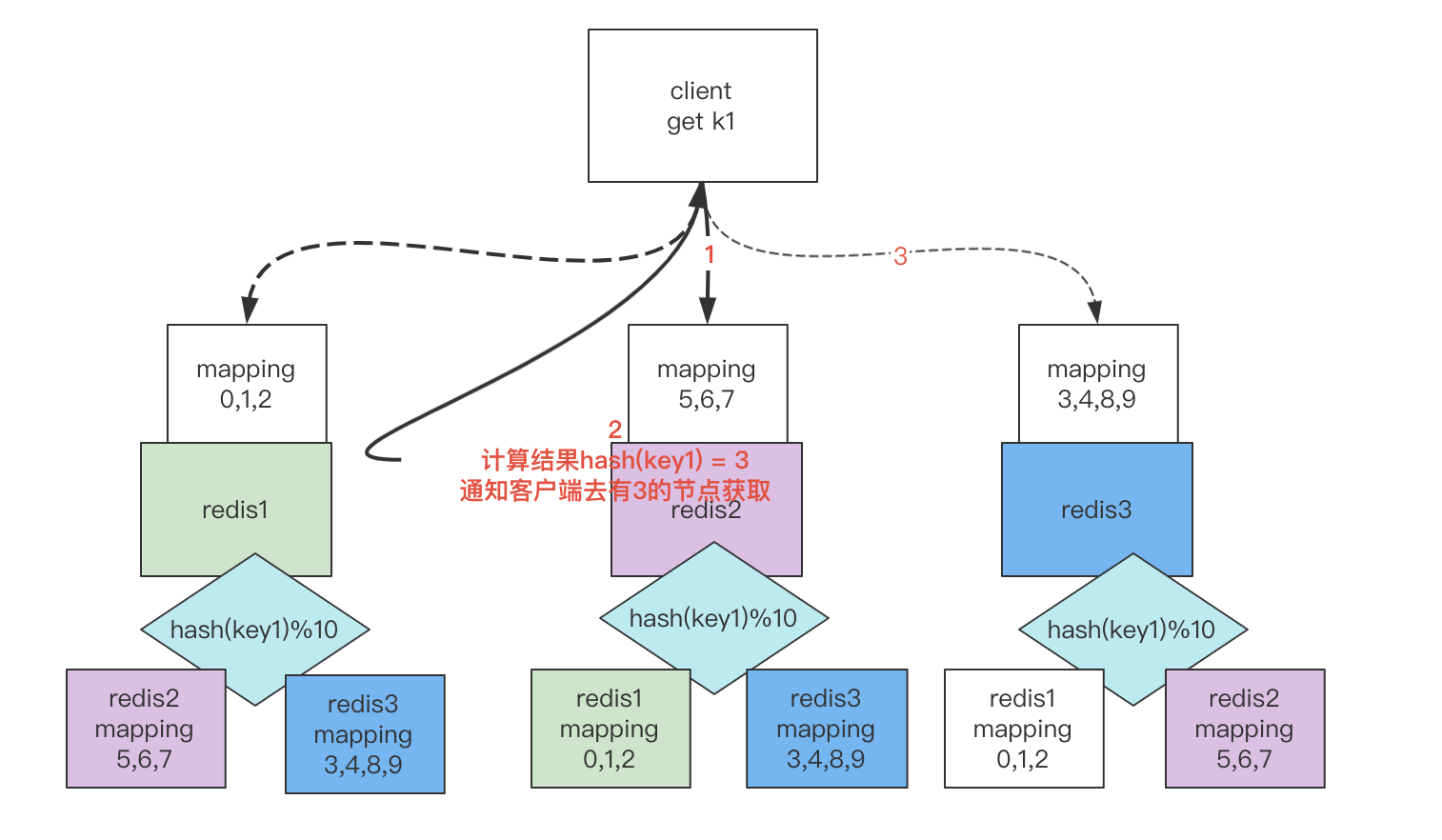 每个节点存一份
每个节点存一份数据-节点映射关系表,比如redis1节点存放的是0,1,2的hash值对应的数据,redis1为5,6,7,此时用户请求获取key1,其hash值为3。
-
此时将请求路由到了redis2/redis1节点,而这2个节点又不存储该数据。
-
在redis2里获取到了key1的值hash值为3,拿了到映射表的关系,哦,数据在redis3,通知客户端去redis3获取。
-
客户端去redis3获取数据。
文章对你有帮助的话,动动小手点个赞或者留下你的评论,让我知道:我和你在并肩战斗。